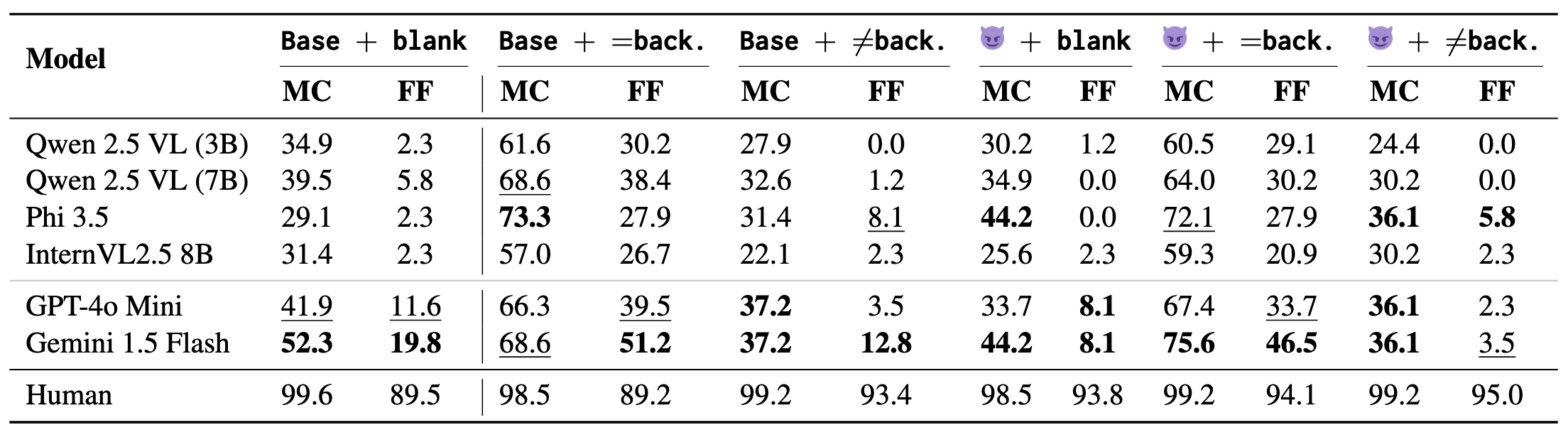
Can Vision Language Models Understand
Mimed Actions?
1
 3
3
ACL 2025 Findings
3
@misc{cho2025visionlanguagemodelsunderstand,
title={Can Vision Language Models Understand Mimed Actions?},
author={Hyundong Cho and Spencer Lin and Tejas Srinivasan and Michael Saxon and Deuksin Kwon and Natali T. Chavez and Jonathan May},
year={2025},
eprint={2506.21586},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.21586},
}

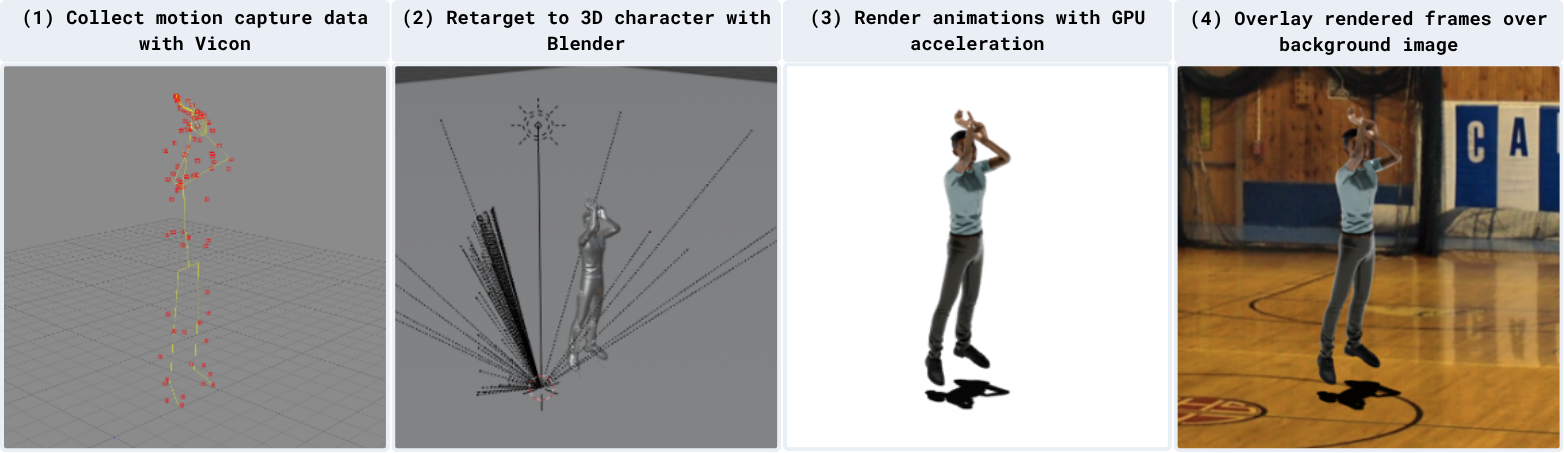

 in a sci-fi spacesuit.
in a sci-fi spacesuit.